Introduction:

In the world of data analytics and engineering, dbt (data build tool) has gained significant popularity for its ability to transform and model data within a data warehouse. dbt Cloud, an advanced version of dbt, provides a collaborative and scalable environment for managing dbt projects and orchestrating data transformation jobs. This article will guide you through the process of linking a dbt Cloud instance with a Django project, allowing you to seamlessly manage projects and trigger data transformations.
Prerequisites:
Before proceeding, ensure that you have the following:
- A Django project set up and running.
- A dbt Cloud account with an active instance.
Step 1: Configuring Django Settings
In your Django project, navigate to the settings.py file and add the following configuration variables:
# DBT CONFIGURATION
DBT_BASE_URL = os.getenv("DBT_BASE_URL", "https://cloud.getdbt.com/api")
DBT_TOKEN = os.getenv("DBT_TOKEN", None)
DBT_ACCOUNT_ID = os.getenv("DBT_ACCOUNT_ID", "23489")
The environment variables, namely DBT_BASE_URL, DBT_TOKEN, and DBT_ACCOUNT_ID, are crucial for connecting a dbt Cloud instance with a Django project. These variables serve as configuration options that enable communication between your Django application and dbt Cloud, granting access to its functionalities.
DBT_BASE_URL: This variable sets the base URL for the dbt Cloud API, typically set as "https://cloud.getdbt.com/api" by default. It defines the endpoint where your Django application interacts with dbt Cloud, facilitating project and job management.DBT_TOKEN: This variable holds the access token required for authentication with dbt Cloud. It ensures secure communication between your Django application and dbt Cloud's API. Make sure to obtain the token from your dbt Cloud account and keep it confidential.DBT_ACCOUNT_ID: This variable specifies the account ID associated with your dbt Cloud instance. The account ID assists in identifying and authenticating your specific dbt Cloud account within the system.
By incorporating these environment variables into your Django project's settings, you establish the necessary connection between dbt Cloud and your application. This connection empowers you to seamlessly retrieve projects, manage jobs, and trigger data transformations.
Step 2: Setting up the dbt Cloud Client
In our scenario, we have developed our own architecture for integrating third-party APIs. Our architecture follows a modular concept, aiming to separate concerns into distinct components: the Client and the Provider.
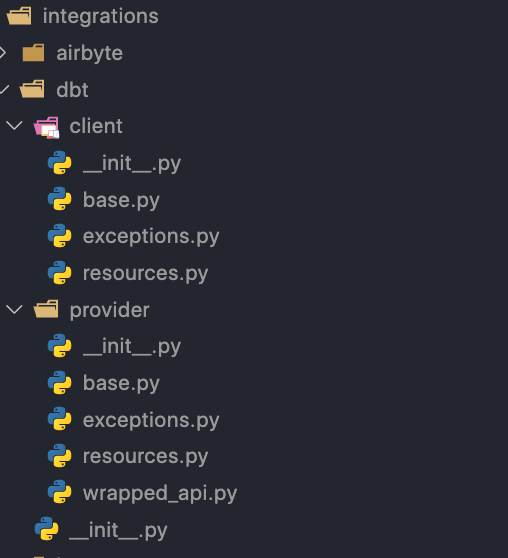
At the client’s level, we’re trying to encapsulate the Dbt Api exceptions, resources as data classes, inputs and outputs of the client methods.
The rest of BE should interact exclusively with the client (class) and should not care about the actual Dbt API calls which are delegated separately to the provider classes.
# client/__init__.py
"""
This Contains the client implementation based on the interface defined in base.py:
- All the abstract methods should be implemented (NotImplementedError will be raised otherwise).
- Any Exchange with Dbt should be made through this client.
- No low level API calls should me made directly in he client, but through the provide classes instead.
"""
class DbtClient(IClient):
"""
Dbt client
"""
def __init__(self, company_id: Optional[int] = None):
self._provider = DbtProvider()
self._company_id = company_id
def _get_client_context(self, request_type: RequestType):
"""
Construct a client context
"""
return ClientContext(
client_type=CLIENT_TYPE,
request_uuid=str(uuid4()),
request_type=request_type,
company_id=self._company_id,
)
def list_projects(self, accountId) -> str:
"""
List projects
"""
# client context is a set of auxiliary data passed from client to provider to: help perform the request, traceability etc...
client_context = self._get_client_context(RequestType.LIST_PROJECTS)
# Make call to provider's list_projects()
data = self._provider.list_projects(
client_context=client_context, accountId=accountId
)
return data
def trigger_job(self, accountId: str, jobId: str, cause: str) -> str:
"""
Trigger a job
"""
# client context is a set of auxiliary data passed from client to provider to: help perform the request, traceability etc...
client_context = self._get_client_context(RequestType.TRIGGER_JOB)
# Make call to provider's list_jobs()
data = self._provider.trigger_job(
client_context=client_context, accountId=accountId, jobId=jobId, cause=cause
)
return data
The Provider class is the contact point with client. It has the role of making API calls through the wrapper_api.py class(es) making any preliminary cleanup or transaformations to the raw data before returning them to the client caller method.
# provider/__init__.py
class DbtProvider:
"""
Provider class for DBT
"""
def __init__(self) -> None:
self._api: IWrappedAPI = DbtWrappedAPI()
def list_projects(self, client_context: ClientContext, accountId: str) -> Dict:
with provider_request(
client_context=client_context,
request_type=RequestType.LIST_PROJECTS,
fn_args={"accountId": accountId},
) as provider_request_context:
response = self._api.list_projects(accountId=accountId)
serialized_response = {
"status_code": response.status_code
} # we can pass the whole response when needed
provider_request_context.add_response(serialized_response)
return response.json()
def trigger_job(
self, client_context: ClientContext, accountId: str, jobId: str, cause: str
) -> Dict:
with provider_request(
client_context=client_context,
request_type=RequestType.TRIGGER_JOB,
fn_args={"accountId": accountId, "jobId": jobId, cause: cause},
) as provider_request_context:
response = self._api.trigger_job(
accountId=accountId, jobId=jobId, cause=cause
)
serialized_response = {
"status_code": response.status_code
} # we can pass the whole response when needed
provider_request_context.add_response(serialized_response)
return response.json()
To ensure code sustainability and clarity, we depend on the wrapped_api.py file for the implementation of all API calls.
# provider/wrapped_api.py
class DbtWrappedAPI(IWrappedAPI):
"""
Dbt WrappedAPI
"""
CONNECT_TIMEOUT = 5
READ_TIMEOUT = 120
# server url (usually it would live in a var env)
DBT_BASE_URL = settings.DBT_BASE_URL
headers = {
"Content-Type": "application/json",
"Authorization": f"Token {settings.DBT_TOKEN}",
}
def _process_response(
self, response: Response, raise_error: bool = True
) -> Response:
"""
Checks the response process the Json/Logs/raises error accordingly
"""
try:
response.raise_for_status()
except HTTPError as e:
sentry_sdk.capture_exception(
e
) # to make sure we capture all exception's related data in:
# https://airbyte-public-api-docs.s3.us-east-2.amazonaws.com/rapidoc-api-docs.html#post-/v1/state/get,
# auxiliary data are also included: rootCauseExceptionStack...
if raise_error:
try:
message = e.response.json()["message"] # get error message
except:
message = str(e.response)
# raise specific (custom) exceptions to allow capturing/treating them differently at upper layer
if e.response.status_code == 422:
raise UnprocessableEntityError(message=message)
elif e.response.status_code == 404:
raise NotFoundError(message=message)
elif e.response.status_code == 400:
raise InvalidRequestError(message=message)
elif (
e.response.status_code == 429
): # when rate limit is reached, usually HTTP 429 is returned
raise TooManyRequestsError(message=message)
return response
def list_projects(self, accountId: str) -> Dict:
"""
Use the List Projects endpoint to list the Projects in the specified Account
GET https://cloud.getdbt.com/api/v2/accounts/{accountId}/projects/
"""
endpoint_url = f"{self.DBT_BASE_URL}/v2/accounts/{accountId}/projects/"
payload = {"accountId": accountId}
data = json.dumps(payload)
response = requests.get(
endpoint_url,
data=data,
headers=self.headers,
timeout=(self.CONNECT_TIMEOUT, self.READ_TIMEOUT),
)
return self._process_response(response=response)
def trigger_job(self, accountId: str, jobId: str, cause: str) -> Dict:
"""
Use this endpoint to kick off a run for a job
POST https://cloud.getdbt.com/api/v2/accounts/{accountId}/jobs/{jobId}/run/
"""
endpoint_url = f"{self.DBT_BASE_URL}/v2/accounts/{accountId}/jobs/{jobId}/run/"
payload = {"cause": cause}
data = json.dumps(payload)
response = requests.post(
endpoint_url,
data=data,
headers=self.headers,
timeout=(self.CONNECT_TIMEOUT, self.READ_TIMEOUT),
)
return self._process_response(response=response)
The code provided showcases a DbtWrappedAPI class that serves as a wrapper for interacting with the dbt Cloud API. It includes methods for listing projects and triggering jobs within the dbt Cloud instance. Here's a breakdown of the key elements in the code:
- The class
DbtWrappedAPIimplements theIWrappedAPIinterface, indicating its role as a wrapper for the dbt Cloud API. - The
DBT_BASE_URLvariable holds the base URL for the dbt Cloud API, obtained from the Django settings assettings.DBT_BASE_URL. - The
headersdictionary contains the necessary headers for making authenticated requests to the dbt Cloud API, including the authorization token obtained fromsettings.DBT_TOKEN. - The
_process_responsemethod handles the response received from the API, raising appropriate exceptions based on the status code and capturing exceptions using Sentry. - The
list_projectsmethod retrieves a list of projects associated with the specified account ID. It sends a GET request to the appropriate endpoint using therequestslibrary. - The
trigger_jobmethod triggers a run for a specific job. It sends a POST request to the corresponding endpoint, including a payload with the cause of the job run.
Overall, this code provides a convenient way to interact with the dbt Cloud API by encapsulating the necessary HTTP requests and error handling logic within the DbtWrappedAPI class.
Step 3: Backend Api call
In our current configuration, we have completed the necessary setup. Now, to retrieve a list of projects, we need to make a backend API call. For this purpose, we rely on the Viewsets, which handle all interactions with the web interface.
# apis/dbt/views.py
@action(detail=True, methods=["get"])
def list_projects(self, request, pk=None):
account_id = request.query_params.get("account_id")
projects = list_projects(account_id)
if isinstance(projects, dict):
return Response(projects, status=status.HTTP_200_OK)
serializer = ProjectSerializer(data=projects, many=True)
if not serializer.is_valid():
pass
data = serializer.data
paginator = LargeResultsSetPagination()
page = paginator.paginate_queryset(data, request)
if page is not None:
return paginator.get_paginated_response(page)
return Response(data)
This code allows the API to handle a GET request to list projects based on the provided account ID. It retrieves the projects, serializes them, applies pagination if needed, and returns the appropriate API response.
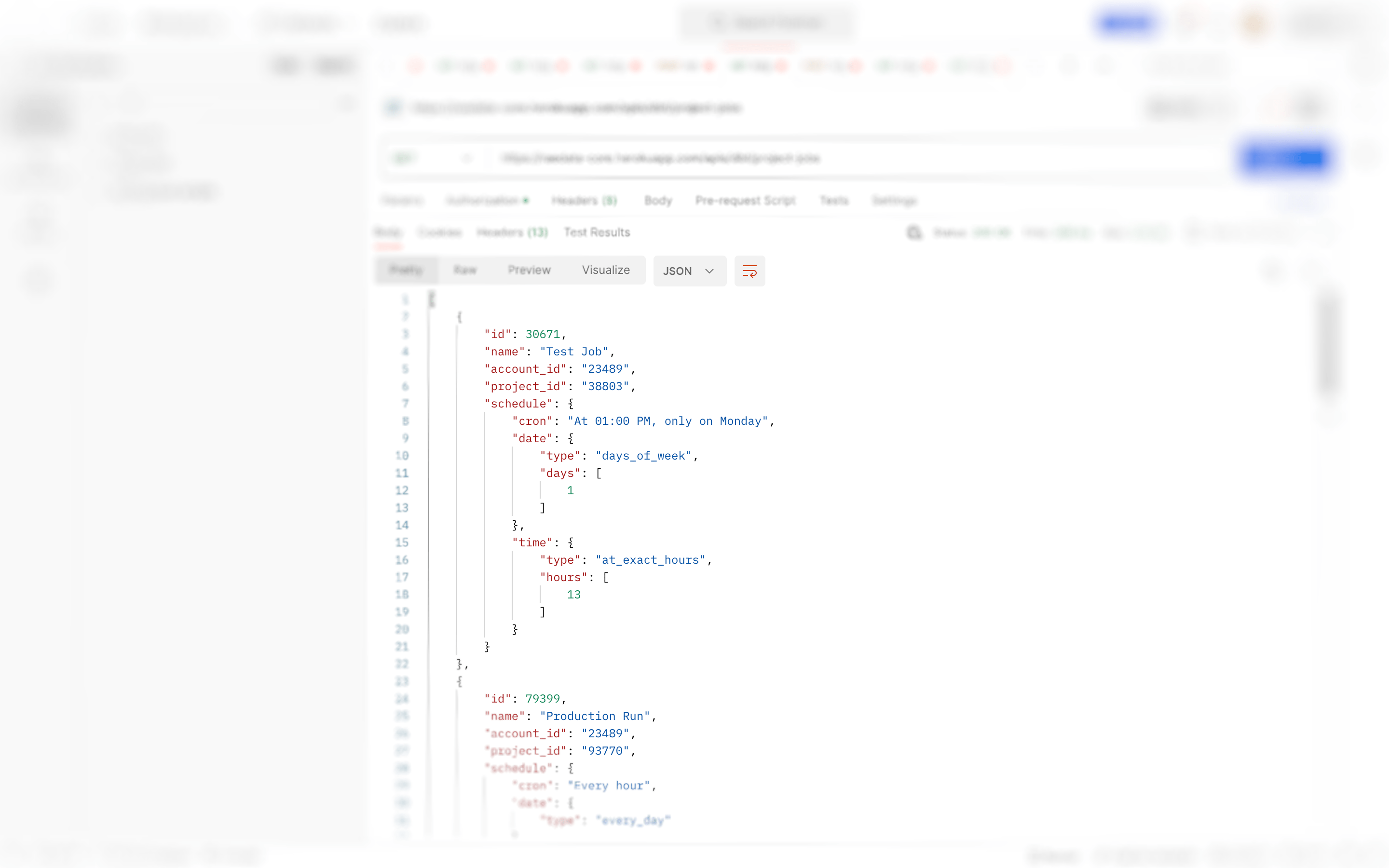
Results :
Voilà ! as you can see here, the returned payload contains jobs fetched from different projects associated to one account
Conclusion:
By integrating your Django project with dbt Cloud, you can efficiently manage dbt projects, retrieve jobs associated with projects, and trigger data transformations. This article provided a step-by-step guide to establish the connection, retrieve projects and jobs, and trigger jobs. Utilizing the power of dbt Cloud within your Django application enhances your data engineering capabilities and streamlines your data transformation workflows.
Remember to refer to the official documentation of dbt Cloud and Django for further customization and exploration of available features.
Happy data transforming!